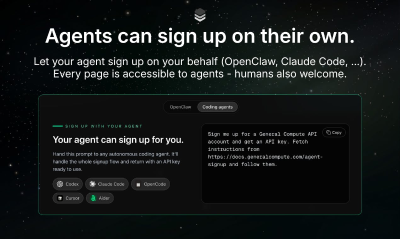
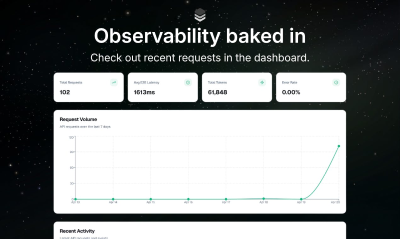
Traditional GPUs are primarily optimized for AI training, not for efficient inference. General Compute addresses this by providing a specialized inference cloud powered by ASICs, which are custom-designed alternatives to standard Nvidia silicon, engineered exclusively for inference workloads. This dedicated architecture allows us to deliver responses that are up to 5 times faster and achieve significantly higher per-user throughput, which is crucial for latency-sensitive applications such as coding assistants and real-time voice agents. With our OpenAI-compatible API, integrating General Compute is straightforward; simply update your base URL to leverage our powerful infrastructure, seamlessly maintaining your current workflows while benefiting from real-time AI performance on hardware purpose-built for the task.



Categories:
Launch Team / Built with
Launch Date:
May 27, 2026
Product Info
Awards
#3 of the Day
#4 of the Week